
Relying on prompt-tweaking and manual oversight to guide AI behavior is like fixing a self-driving car by remote control. If your AI agents can’t optimize themselves, they will eventually slow down the systems/workflows they are meant to enhance. So, how do you make self-improving AI agents?
Most AI agents today follow a predictable lifecycle: design, deploy, tweak, repeat. They rely heavily on hand-crafted prompts or periodic retraining to stay accurate. That process is fragile, slow, and resource-heavy.
There’s growing interest in building agents that can adjust themselves, optimizing how they reason, respond, and operate based on their performance.
Before we explore what a self-improving AI agent looks like, let’s address why the current approach, prompt engineering, is not enough.
Why It’s Hard to Improve AI Agents Using Traditional Prompt Engineering
Prompt engineering was a necessary starting point. It provided a way to interact with language models directly by tuning inputs, testing phrasing, and iterating manually. However, as use cases of AI agents have grown more complex, the limitations of prompt engineering have become harder to ignore. Here’s why Most prompt engineering workflows are:
- Unstructured: Each prompt acts like a one-off experiment with limited reusability.
- Opaque: Failures are hard to trace. When output quality drops, it’s hard to understand why it happened.
- Manual: Improvement depends on human intuition, tweaking phrasing, adding examples, and re-running tests.
- Non-systematic: There’s no built-in feedback loop or optimization mechanism.
For simple tasks, that might be manageable. But for multi-step reasoning, long-horizon workflows, or agents interacting across tools and data layers, it’s not enough.
What Is a Self-Improving AI Agent?

In response to these limitations, a new class of agents is emerging that is designed to adapt, learn, and refine without human-in-the-loop edits. We are talking about self-improving AI agents.
At its core, these agents are designed not just to perform a task but to continuously refine how they perform that task based on feedback, evaluation, or internal optimization.
The focus isn’t on modifying the language model itself. Instead, what truly drives adaptability is how the surrounding system is designed, its reasoning flow, modular setup, and capacity to evolve without touching the underlying model.
A self-improving AI model usually reflects three foundational traits:
- Performance Awareness: It can monitor how well it’s doing relative to its intended goals.
- Flexible Architecture: Its structure is designed for adaptability, where prompts, reasoning steps, or toolkits can be swapped or updated seamlessly.
- Self-Optimization: The agent uses internal signals or feedback to fine-tune its own processes over time without external reprogramming.
Unlike static pipelines, these agents aren’t hardcoded. They operate as feedback-sensitive systems, where execution traces can be collected, evaluated, and compiled into a more effective configuration, all while the underlying language model remains unchanged.
This shift from tweaking prompts to optimizing pipelines helps in scalable and production-ready AI agent development.
Understanding the Spectrum of Self-Improving Agents
As we move toward more autonomous AI systems, not all self-improvement models are created equal. It unfolds along a spectrum from narrow adaptability to expansive, architecture-level evolution. Understanding this continuum is key to shaping both the opportunities and limits of intelligent agents.
Let’s explore three illustrative modes:
1. Narrow Self-Improvement: Focused and Localized
These agents improve within a fixed context or goal. Their architecture stays the same, but they optimize performance through data refinement, retraining, or behavioral tuning.
For instance, an LLM-powered agent that detects degradation in performance might:
- Automatically launch a fine-tuning loop
- Adapt to new data distributions
- Refine its decision logic using prior feedback
This is the most immediate and practical form of self-improvement and the kind DSPy readily supports.
2. Broad Self-Improvement: Expansive and Creative
In contrast, broad self-improvement refers to agents that modify their capabilities, expand their toolsets, or restructure their workflows entirely. They might:
- Write new functions or tools
- Design sub-agents to handle subtasks
- Alter their internal architecture to optimize reasoning
This isn’t just getting better; it’s getting different. Agents operating at this level begin to exhibit recursive tendencies, improving the very mechanisms that drive improvement. It edges closer to what’s often dubbed intelligence explosion.
3. Hybrid and Emergent Modes: The Middle Ground
Many real-world systems won’t fall neatly into either camp. Take an agent that:
- Uses data augmentation to boost performance
- Adapts to related (but not predefined) tasks
- Learns generalized capabilities that apply to new contexts
This sits between narrow and broad improvement, not just task-tuning but also skill acquisition that transcends single-goal optimization. These agents operate with a form of meta-cognition, improving outcomes and their approach to unfamiliar challenges.
Framing self-improvement this way allows developers and decision-makers to choose the right ambition level and align infrastructure, safety, and oversight accordingly.
How DSPy Framework Helps in Developing Self-Improving Agents
To implement these self-improving capabilities in practice, you need an architecture designed for evolution. We are talking about the DSPy framework.
DSPy doesn’t just abstract prompt logic; it systematizes language model development around a structured pipeline. The DSPy framework structures its optimization pipeline around four essential stages: sourcing effective training inputs, shaping intelligent programs, executing streamlined inference, and applying targeted evaluation to guide improvements.
1. Training Data: The Foundation of Self-Improvement
At the core of DSPy’s architecture is high-quality training data based on volume and precision. DSPy agents learn from execution traces collected during development, where inputs, intermediate reasoning steps, and outputs are stored as reusable supervision examples.
This data directly drives optimization. The cleaner and more representative it is, the better the agent performs. Poor data compounds failure, while gold-quality examples act as high-leverage tuning points.
2. Program Training: From Static Logic to Optimized Pipelines
DSPy introduces built-in optimizers that refine how agents reason and respond. These tools train the pipeline by tuning how logic is composed around the model. Key optimizers include:
- BootstrapFewShot: Selects high-impact training examples for few-shot learning.
- BootstrapFewShot + Random Search: Explores larger combinations of examples for better generalization.
- MIPROv2: A more advanced optimizer that not only selects data but generates full, prompt instructions for stronger results.
All optimized programs are cached in a knowledge base, allowing for rapid reuse without retraining.
3. Inference: Fast, Structured, and Reusable
During runtime, DSPy uses the cached, optimized programs to run inference with minimal overhead. Instead of generating logic from scratch, it uses what it’s already learned by executing multi-step reasoning workflows with efficiency and traceability. Inputs are fed through optimized modules, and outputs flow directly into the evaluation layer.
4. Evaluation: Where Self-Improvement Starts Again
DSPy incorporates a built-in evaluation framework designed for comparative testing. Developers can run DSPy-powered agents against control agents using the same inputs, workflows, and tools, creating apples-to-apples benchmarks.
One standout feature is the semanticF1 metric: an LLM-based evaluator that assesses output quality in terms of both meaning and precision. It’s a more nuanced alternative to surface-level scoring and is essential to DSPy’s optimization loop.
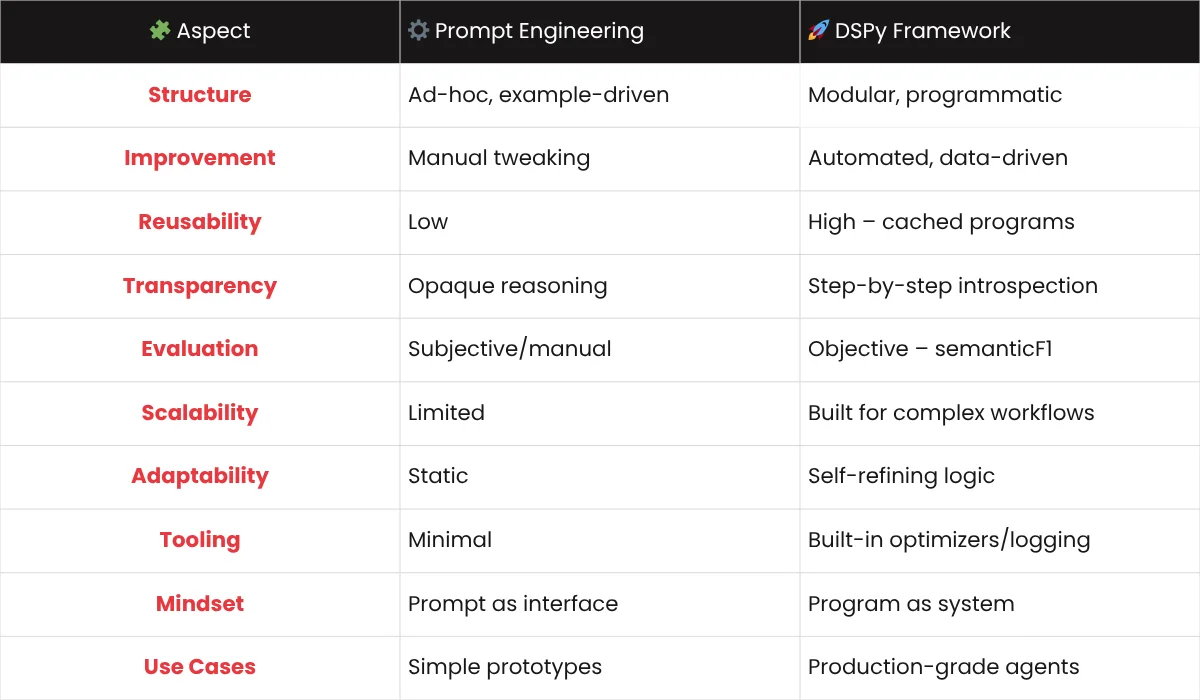
Prompt Engineering vs. DSPy Framework: A Comparison
Conclusion
As language models mature, the real leap isn’t in making them larger; it’s in making them smarter about themselves. Systems that can adapt, critique, and evolve don’t just reduce engineering overhead; they mark the shift from AI as a tool to AI as a dynamic collaborator.
DSPy is a powerful catalyst for this shift. It brings structure, clarity, and discipline to the way we build adaptive AI systems. By moving us beyond the limitations of prompt engineering into modular, measurable self-improvement pipelines, DSPy represents a new design philosophy, one that forward-thinking AI leaders will need to embrace to stay ahead of the curve and build self-improving AI agents responsibly.






