
AI agents fail in a particular way. Not because they give the wrong answer once, but because they behave unpredictably across workflows. They nail the demo, then misuse a tool in step four of a pipeline. They pass unit tests, then lose context mid-conversation. They score well on benchmarks, then drift quietly in production.
The core problem is that everything we know about software testing assumes a deterministic system. Same input → same output. You write assertions, check return values, and call it done.
AI agent testing doesn’t work that way.
Why Standard Testing is Not Right for AI Agents

Four properties of AI agents make them fundamentally untestable with conventional tools:
- Non-Determinism: The same prompt can produce meaningfully different outputs across runs. A test that passes today may fail tomorrow with no code change.
- Multi-Turn Complexity: Agents plan and execute over multiple steps. So, if they fail at one step, the result will be wrong across every step.
- Tool and API Dependencies: Real agents call external APIs, query databases, and write files. Testing must account for what happens when those tools are misused, slow, or unavailable.
- Context Retention: Does the agent remember what the user said three turns ago? Does it maintain its objectives when interrupted? These are behavioural questions.
How Frameworks Help in AI Agent Testing?
AI agent testing frameworks are specialized systems built for one purpose: evaluating how agents behave, not just what they output. Concretely, they are designed to:
- Evaluate non-deterministic outputs fairly across multiple runs
- Test multi-step reasoning and planning across turns
- Validate how agents use tools and maintain context over time
They shift the focus from “did the agent return the right string?” to “did the agent handle this task reliably under realistic conditions?” This distinction matters. A response can be semantically correct but structurally wrong. The agent used the right tool at the wrong time, or answered accurately but hallucinated a reasoning step.
6 Key Frameworks to Test Your AI Agent Correctly
Here are the frameworks engineers are actually using, with a clear sense of what each one is best suited for.
-
Arbigent: UI-Level Agent Testing
Tests agents interacting directly with UI elements in dynamic web and mobile applications. Designed to reduce flaky UI tests by letting agents reason about interface state rather than relying on brittle selectors.
Best for: Web and app interface agents
-
DeepEval: LLM & Agent Evaluation
Structured evaluation framework supporting LLM apps, RAG pipelines, and full agents. Offers custom metrics out of the box: bias, toxicity, correctness, hallucination rate, and contextual relevance.
Best for: Scoring and structured evaluation
-
Rogue: Agent-to-Agent Testing
Uses AI agents to test other AI agents. Validates policy compliance and functional behaviour by simulating adversarial inputs, edge cases, and unexpected interaction patterns autonomously.
Best for: Autonomous system validation
-
LangWatch: Simulation-Based Testing
Focuses on multi-turn conversation testing using realistic user interaction patterns. Runs agents through simulated dialogues that mirror actual user behaviour, surfacing context drift and failure modes that single-turn tests miss.
Best for: Conversational agents
-
Galileo AI: Observability & Benchmarking
Combines benchmark datasets with continuous performance tracking. Monitors agents in production to detect behaviour drift, regressions, and anomalies over time, not just at evaluation checkpoints.
Best for: Monitoring at scale
-
Microsoft Agent Framework: Enterprise Workflows
Built for multi-agent orchestration at enterprise scale. Supports validation of complex agent pipelines where multiple specialized agents coordinate, with built-in monitoring and handoff testing.
Best for: Enterprise multi-agent systems
Core Testing Methodologies for AI Agents
These AI agent testing frameworks share three approaches. Understanding them helps you know why each tool works and where it falls short.
-
Agent Evaluations (Evals)
Outputs are scored across multiple dimensions: accuracy, reasoning quality, tool usage, and safety. Evals create a structured record of how an agent performs across many inputs, making it possible to detect and track failure patterns rather than investigating one-offs.
-
Simulation-Based Testing
Agents are placed in sandbox environments that mimic real users, edge cases, and unexpected inputs. This is where real-world failures surface because they come from conditions you didn’t anticipate when writing tests. Simulation creates those conditions systematically.
-
Continuous Evaluation
Monitoring agents in production for behaviour drift and performance changes over time. Testing doesn’t stop at deployment. Model updates, new user patterns, and data distribution shifts can all cause agent behaviour to degrade silently.
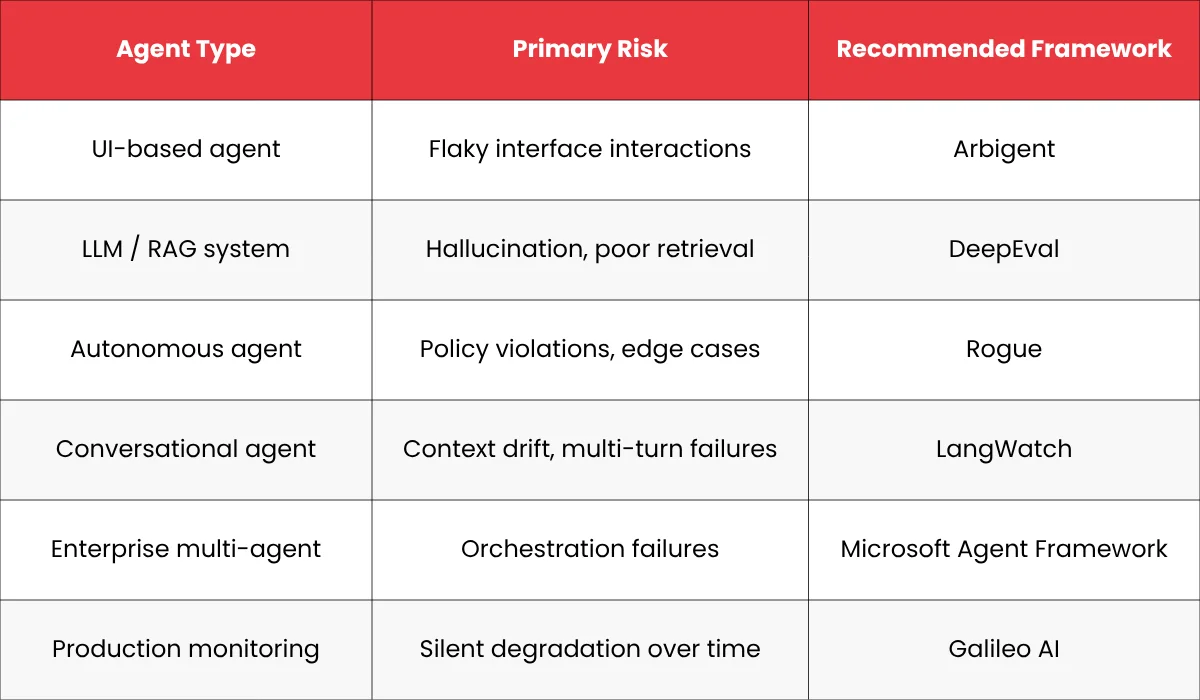
How to Choose the Right Framework for AI Agent Testing
Different agent types have different failure modes. Your framework choice should map to the failure mode you are most concerned about.
How These Frameworks Work Together
No single framework covers the full lifecycle of an AI agent, so use a mix of frameworks:
- Simulation (LangWatch): Test in realistic conditions before deployment
- Evaluation (DeepEval): Score outputs across quality dimensions
- Specialised Testing (Arbigent / Rogue / Microsoft): Handle domain-specific edge cases
- Continuous Monitoring (Galileo AI): Track behaviour drift post-deployment
Common Gaps, Even With Frameworks
Having the right tools doesn’t automatically mean effective testing. These are the gaps teams consistently fall into:
- Over-relying on eval scores: A high score doesn’t mean correct behaviour in context. Scores are signals, not verdicts.
- Unrealistic test scenarios: Synthetic test cases miss the distribution of real user inputs. Simulation needs real-world grounding.
- Ignoring production feedback: What users actually do differs from what you tested for. Production logs are a testing dataset.
- No human-in-the-loop: Automated metrics can’t catch everything. High-stakes agents need periodic human review of outputs.
Conclusion
AI agent testing frameworks don’t just validate outputs; they validate behaviour across real-world conditions. The shift from output testing to behaviour testing is the shift from “does this work in my terminal” to “does this work for users, reliably, over time.”
FAQs
What are AI agent testing frameworks?
AI agent testing frameworks are systems designed to evaluate how AI agents behave across tasks, not just their final outputs. They test multi-step reasoning, tool use, and context handling using methods such as simulations, evaluations, and continuous monitoring.
How are AI agent testing frameworks different from traditional testing tools?
Traditional testing tools validate fixed outputs against expected results. AI agent testing frameworks evaluate non-deterministic behaviour, meaning they assess how an agent makes decisions, uses tools, and performs across multiple scenarios rather than a single response.
Why is testing AI agents more complex than testing LLMs?
LLMs generate single responses, while AI agents perform multi-step tasks that involve planning, memory, and tool use. This adds layers of complexity, making it necessary to test workflows, intermediate steps, and decision-making processes, not just final outputs.
What are “evals” in AI agent testing?
Evals (evaluations) are methods used to score AI agent performance. They measure factors like accuracy, relevance, safety, and reasoning quality. Most frameworks rely on automated evaluations or LLM-based judges to test agent performance at scale across large datasets.
What is simulation-based testing for AI agents?
Simulation-based testing places AI agents in controlled environments that mimic real-world scenarios. It helps test how agents behave in multi-turn conversations, edge cases, and unexpected inputs before deploying them in production.
What are the biggest challenges in AI agent testing?
The main challenges include handling non-deterministic outputs, testing multi-step workflows, validating tool usage, creating realistic test scenarios, and maintaining consistent performance across different environments.
How do you reduce hallucinations in AI agents during testing?
Hallucinations can be reduced by using structured evals, grounding responses with retrieval systems (RAG), testing against benchmark datasets, and continuously monitoring outputs in real-world scenarios.






