
Enterprises are collecting more data than ever, from apps, APIs, sensors, and cloud platforms. The real struggle isn’t getting data; it’s organizing, processing, and delivering it fast enough to support analytics, AI models, and business decisions.
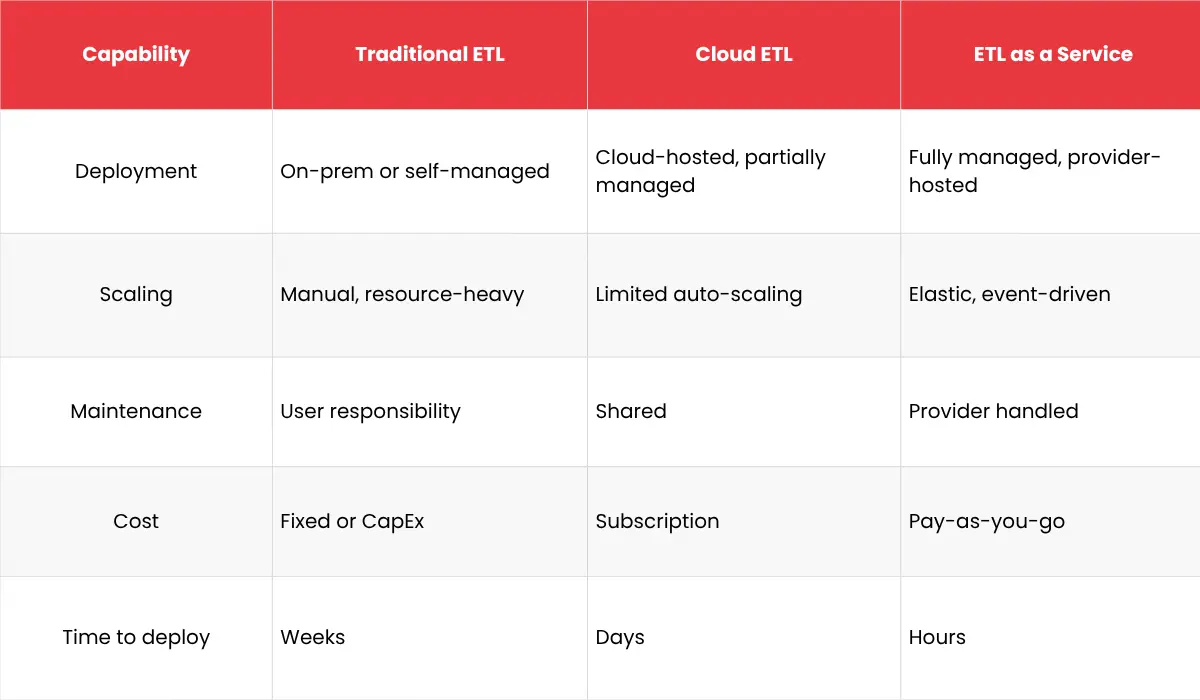
Traditional ETL systems weren’t designed for this pace. They handle fixed schemas, batch updates, and on-prem environments well, but struggle when data lives across multi-cloud platforms or streams in real time.
So teams end up firefighting: maintaining brittle pipelines, fixing schema breaks, scaling compute manually, and waiting hours (or days) for data refreshes.
That’s the gap ETL as a Service (ETLaaS) fills. It turns complex, infrastructure-heavy ETL operations into a fully managed cloud service, one that automatically scales, adapts to new sources, and keeps data flowing with minimal human intervention.
In other words, ETLaaS lets engineers spend time building intelligence, not maintaining pipelines.
What is ETL as a Service (ETLaaS)?
ETL as a Service delivers Extract, Transform, Load capabilities through a cloud-managed platform, so you don’t have to host, configure, or orchestrate pipelines yourself.
Unlike traditional or semi-managed tools, ETLaaS platforms handle everything from resource scaling to job monitoring and security compliance, out of the box.
Key characteristics of ETLaaS:
- No infrastructure burden: The service handles clusters, updates, and orchestration.
- Wide connector library: Ready-made integrations for cloud apps, APIs, databases, and flat files.
- Smart transformations: Schema recognition, data validation, and cleansing built in.
- Observability baked in: Dashboards for lineage, job status, and failure alerts.
- Enterprise-grade security: Encryption, role-based access, and compliance support.
ETLaaS also fits naturally into modern ELT or lakehouse architectures, letting teams push transformations downstream into Snowflake, BigQuery, or Databricks when needed.
The result: simpler pipelines, faster deployment, and more reliable data delivery, without the operational overhead of traditional ETL tools.
Also Read: 5 Free Tools for Data Visualization
Why Traditional ETL Models Fall Short
Legacy architectures were built for a simpler world, when data mostly lived on-prem, pipelines ran overnight, and “real time” meant a daily refresh. That world doesn’t exist anymore.
Modern data teams now deal with unstructured data, hybrid environments, and constant schema evolution. Traditional ETL can’t keep up because it was never meant to.
Here’s where the cracks show up:
- Rigid infrastructure: Pipelines depend on fixed servers and storage. Scaling up means manual provisioning or expensive hardware upgrades.
- High maintenance cost: Engineers spend disproportionate time debugging failures, scheduling jobs, and updating connectors instead of improving models or analytics.
- Latency issues: Batch-only processing causes delays between data generation and availability, which kills real-time analytics use cases.
- Limited adaptability: Adding a new data source or updating schemas often means re-engineering the pipeline.
- DevOps dependency: Even small changes can involve multiple teams, data, infra, and ops, slowing down delivery cycles.
The result: data teams get stuck maintaining pipelines that should have been automated years ago. The opportunity cost is high, not just in engineering hours but in missed agility, as teams can’t respond quickly to business or AI needs.
ETL as a Service flips that dynamic, making data movement an elastic, managed utility instead of a fixed operational liability.
Core Advantages of ETL as a Service

Once teams shift from managing ETL in-house to using ETL consulting services, the difference is immediate, less firefighting, more data velocity, and a lot fewer mishaps.
Let’s unpack what actually changes.
1. Elastic Scalability
ETLaaS scales automatically with data volume.Whether you’re ingesting a few gigabytes from a CRM or terabytes from IoT devices, compute resources expand and contract on demand. No need to manually resize clusters or worry about idle infrastructure costs.
For data engineers, this means predictable performance without performance tuning, the system simply adapts.
2. Faster Time to Data
Managed ETL platforms come with pre-built connectors for most cloud applications, databases, and APIs. That means onboarding new data sources takes hours, not weeks. Automated schema detection and transformation templates further cut setup time, letting teams deliver data to warehouses or lakes almost instantly.
Speed isn’t just about ingestion, it’s about reducing friction from idea to insight.
3. Operational Efficiency
Traditional ETL stacks demand constant patching, scheduling, and monitoring. ETLaaS automates those layers, giving engineers more time to design models or optimize queries.
Monitoring dashboards, retry mechanisms, and alerting are built in, so data reliability improves while the maintenance load drops. You stop managing cron jobs and start managing outcomes.
4. Cost Optimization
With ETLaaS, you pay for data processed, not for servers sitting idle between runs. The usage-based model aligns cost directly with workload demand, especially valuable when data volumes fluctuate.
Teams also save on infrastructure, DevOps time, and toolchain sprawl, which often costs more than the pipelines themselves.
5. Integrated Governance and Security
Enterprise-grade ETLaaS platforms are built with security and compliance baked in, not added later. Role-based access, encryption, data masking, and audit trails help maintain control across hybrid environments.
For organizations in regulated industries, these baked-in controls make compliance far less painful to manage at scale.
Together, these advantages shift ETL from a maintenance-heavy operation into a scalable data foundation, one that keeps up with business, cloud, and AI demands without constant engineering overhead.
How ETLaaS Simplifies Modern Data Management
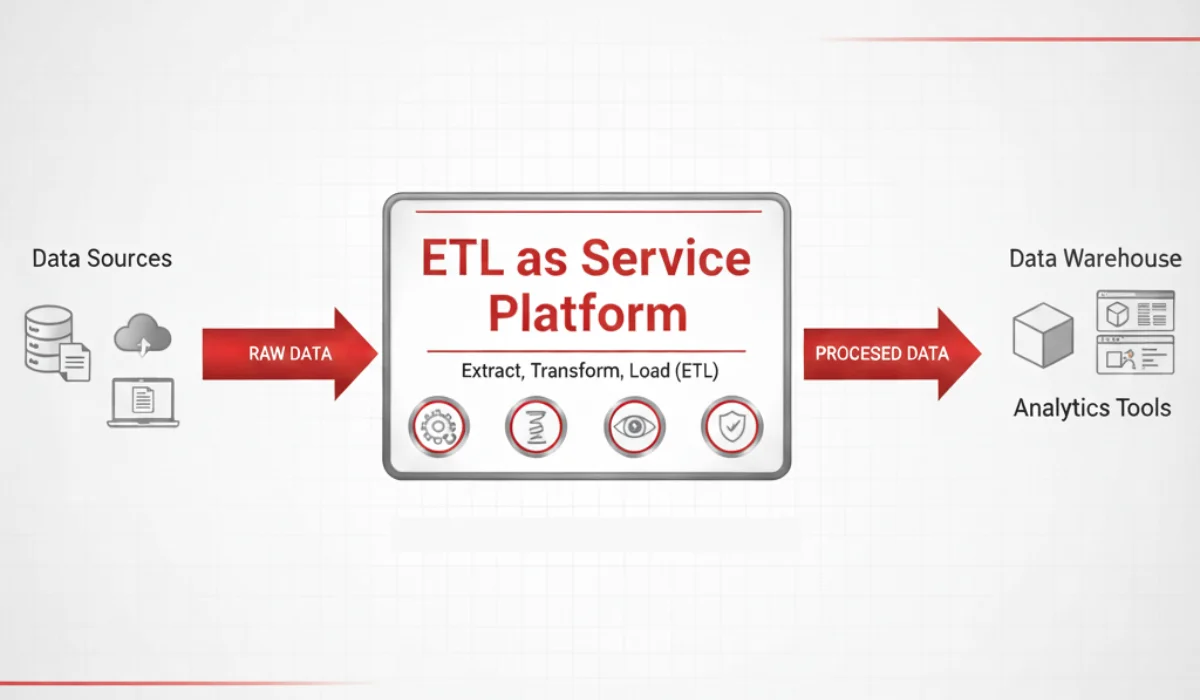
It isn’t just “ETL in the cloud.” It redefines how data flows, scales, and stays trustworthy across a distributed stack. Here’s what that looks like in practice.
1. Unified Data Ingestion Across Diverse Sources
Modern enterprises juggle hundreds of sources, SaaS apps, on-prem databases, APIs, logs, IoT streams.ETLaaS platforms offer a single control plane to connect them all. Pre-built and API-driven connectors unify ingestion so data lands in your warehouse or lakehouse in a consistent format, ready for transformation.
That means fewer custom scripts, fewer integration gaps, and faster onboarding of new sources.
2. Automated Schema Management and Real-Time Sync
Schema drift is one of the most persistent headaches in ETL. ETLaaS tools detect and adapt to schema changes automatically, adding, removing, or mapping fields without breaking the pipeline.
Real-time or micro-batch sync keeps downstream systems continuously updated, supporting live dashboards and AI applications that depend on current data.
3. Built-In Metadata and Lineage Tracking
Understanding where data comes from, and how it transforms along the way, is key to trust.
ETLaaS platforms embed metadata tracking, version history, and lineage visualization into the workflow.
That makes governance and debugging easier: you can trace every field from source to model output without manual documentation.
4. Seamless Integration with Analytics and ML Pipelines
Because ETLaaS is API-first, it plugs directly into orchestration and analytics ecosystems, Airflow, dbt, Kubernetes, or ML pipelines. Data arrives pre-validated and transformation-ready, reducing friction between engineering and data science teams. The result: a cleaner flow from ingestion → transformation → insight.
5. Centralized Monitoring and Observability
Every pipeline, transformation, and data job can be tracked in real time. Dashboards surface latency, throughput, and error trends, while alerting systems flag anomalies early. This makes it easier to maintain SLA-grade reliability without scaling your operations team.
Together, these capabilities simplify the core of data management, ingestion, transformation, reliability, and observability, so teams can move from managing data plumbing to delivering analytics that matter.
Implementation Considerations
Choosing an ETLaaS platform isn’t just about price or connector count. The right ETL consulting services provider should align with your data architecture, operational priorities, and compliance needs. Here’s what to evaluate before committing.
1. Compatibility with Your Existing Stack
Check whether the platform integrates natively with your target systems, data warehouses (Snowflake, Redshift, BigQuery), data lakes (S3, ADLS), and orchestration tools (Airflow, dbt, Prefect).
A good ETLaaS solution should fit into your current ecosystem without forcing architectural rewrites or new coding frameworks.
2. Support for Both Batch and Streaming Data
Data freshness matters.Some ETLaaS platforms still operate on batch-only models, which can introduce latency for event-driven systems.Look for one that supports hybrid pipelines, handling both batch ingestion for historical data and streaming ingestion for live analytics or IoT feeds.
3. API and SDK Extensibility
No matter how many pre-built connectors a provider offers, custom sources will always exist.
Ensure the platform exposes APIs and SDKs for custom connector development, event triggers, and job orchestration. That flexibility lets you evolve your data strategy without waiting for vendor updates.
4. Built-In Transformation Flexibility
Check whether the service supports SQL-based, Python-based, or no-code transformations, whichever matches your team’s workflow. Advanced users often prefer the ability to mix visual design with custom scripting for complex logic. This ensures you can transform data where it makes the most sense, inside the ETLaaS platform or within your data warehouse (ELT model).
5. Observability, Reliability, and SLAs
Data pipelines are mission-critical. Look for providers offering transparent SLAs, uptime guarantees, and detailed monitoring dashboards. You should be able to track latency, job status, and failure logs at a granular level, ideally with integrations into tools like Prometheus or Grafana.
6. Security and Compliance
For regulated industries, security can make or break a deal. The provider should support:
- End-to-end encryption (in transit and at rest)
- Role-based access control (RBAC)
- Data masking and anonymization
- Compliance certifications such as SOC 2, HIPAA, or GDPR
These features ensure your pipelines meet enterprise-grade security expectations without extra tooling.
7. Transparent Pricing and Resource Control
Usage-based pricing sounds good, until you can’t predict the bill. Choose platforms that offer clear cost dashboards, usage alerts, and throttling controls. You should know exactly how data volume, frequency, or transformation complexity impacts spend.
Selecting an ETLaaS provider isn’t about chasing the most features, it’s about choosing the one that matches how your data team works today and scales tomorrow.
Common Use Cases of ETL as a Service

While the technology behind ETLaaS is impressive, its real value shows up in how it simplifies everyday data workflows. Here are some of the most common and high-impact scenarios where teams deploy it.
1. Real-Time Analytics Pipelines
Streaming analytics is no longer a niche capability.Retail, fintech, logistics, and SaaS companies rely on real-time insights to track transactions, monitor system health, or personalize user experiences.
ETLaaS platforms enable continuous data ingestion and transformation, automatically syncing event streams from Kafka, Kinesis, or IoT devices to analytics systems. This keeps dashboards and machine learning models running on fresh, reliable data without manual orchestration.
2. Cloud Migration and Hybrid Data Integration
When organizations modernize from on-prem systems to the cloud, ETLaaS provides a bridge, migrating data securely and incrementally while keeping legacy systems running.
It handles hybrid scenarios where part of the data still resides on-prem and part in cloud warehouses like Snowflake or Redshift, maintaining synchronization across environments without extensive re-engineering.
3. Data Warehouse Modernization
Legacy ETL tools often become the bottleneck when upgrading data warehouses. ETLaaS speeds this transition by automating data movement, deduplication, and transformation logic.
It simplifies building modern lakehouse architectures and supports modular, schema-evolving pipelines, ensuring faster loading times and simplified maintenance.
4. Machine Learning Data Preparation
Data scientists spend a large chunk of time cleaning and structuring data before training models. ETLaaS helps automate that prep stage, handling feature extraction, deduplication, normalization, and joins at scale.
Pipelines can deliver curated datasets directly into ML platforms or feature stores, creating a smoother flow from raw data to production-ready models.
5. Cross-System Data Synchronization
In distributed ecosystems, different teams rely on separate data sources, ERP, CRM, ticketing, and marketing platforms. ETLaaS enables bidirectional or one-way syncs, keeping systems aligned with minimal lag.
This ensures that decision-makers across departments work from the same, up-to-date dataset, critical for consistent reporting and governance.
Each of these use cases reflects the same underlying benefit: ETLaaS turns data movement into a service, removing the operational drag that used to slow down analytics and AI initiatives.
Conclusion
Data management has always been a balancing act, between control and speed, flexibility and stability. Traditional ETL leaned heavily toward control, at the cost of agility.
ETL as a Service rewrites that balance. By abstracting away infrastructure, automating orchestration, and enabling continuous scalability, it lets data engineers focus on what matters: building reliable, adaptive data ecosystems that serve analytics, AI, and real-time decisions.
When data pipelines become a managed service, the conversation moves from “Can we process this data?” to “What can we learn from it?” That’s the promise of ETLaaS: turning complexity into clarity, and data movement into momentum.






