
AI agents are no longer a pilot project curiosity, enterprises are deploying them at scale, across customer support, sales, internal operations, and beyond. But as adoption grows, so does a critical question: how do you actually know if your agent is performing well?
The honest answer is that most teams are measuring the wrong things or not measuring at all. This guide breaks down a practical framework for evaluating enterprise AI agent performance, including the metrics that matter, why traditional AI benchmarks fall short, and how to tie technical indicators to real business outcomes.
Why Traditional Evaluation Metrics Fall Short for AI Agents
When teams first try to measure an AI agent, they reach for familiar benchmarks: accuracy, F1 score, BLEU score. These made sense for classification models and chatbots. They don’t work for agents.
Here’s why: accuracy measures whether a model produces a correct output in isolation. Agents don’t operate in isolation. They complete multi-step workflows, select and invoke external tools, maintain context across a conversation, and make sequential decisions where each step depends on the last.
A single accuracy score collapses all of that complexity into one number and that number tells you almost nothing about whether your agent is actually getting the job done.
Think of agents as systems, not models. Measuring an agent with a single metric is like judging a manufacturing line by the quality of one bolt.
What you need instead is a layered evaluation framework for AI agents, one that captures performance at every level of the agent’s operation.
The 5 Pillars of AI Agent Evaluation Framework
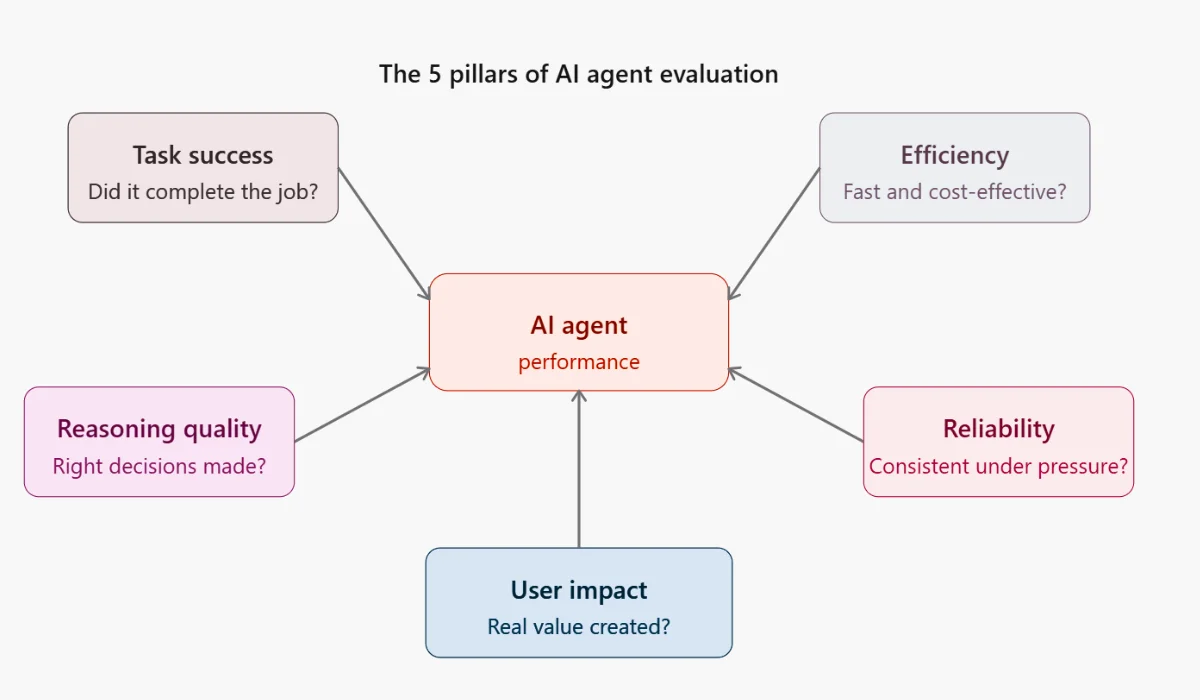
Here is a structured way to think about agent measurement. Every metric worth tracking maps to one of five pillars:
- Task Success: Did the agent complete the job?
- Efficiency: Did it complete the job without wasting time or money?
- Reasoning & Decision Quality: Did it make the right choices along the way?
- Reliability & Robustness: Does it perform consistently, even when things go wrong?
- User Impact: Did it create real value for the people using it?
Task Success Metrics: Did the Agent Actually Complete the Job?
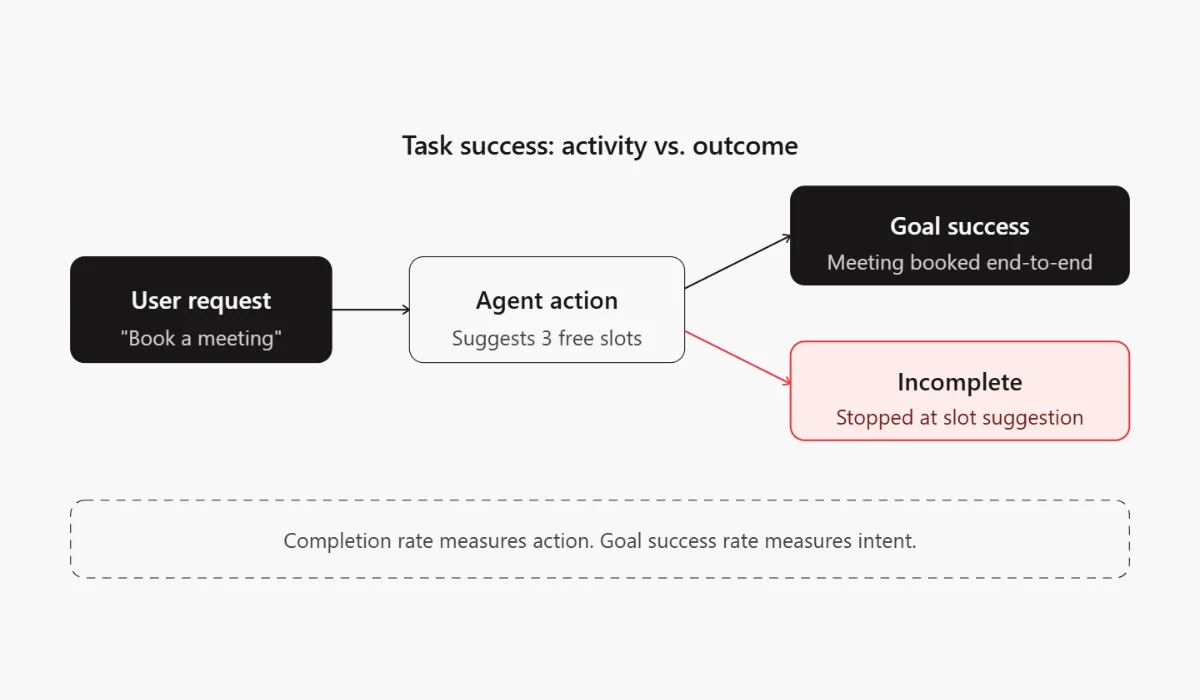
his is the most fundamental question. Before anything else, you need to know whether the agent is actually finishing what it was asked to do.
- Task Completion Rate: The percentage of tasks the agent completes end-to-end without human takeover. This is your baseline health metric.
- Goal Success Rate: Slightly different from completion. Did the agent complete the task in a way that satisfied the original intent? An agent can complete a workflow and still fail the goal.
- Multi-Step Completion Accuracy: For complex workflows, track how accurately the agent navigates each step, not just whether it reaches the end.
Example: An agent asked to “book a meeting” that only suggests available slots has completed an action but it hasn’t completed the task. Distinguish between activity and outcome.
Also Read: How to Measure ROI of AI Agents for Real Business Value
Efficiency Metrics: How Fast and Cost-Effective Is the Agent?
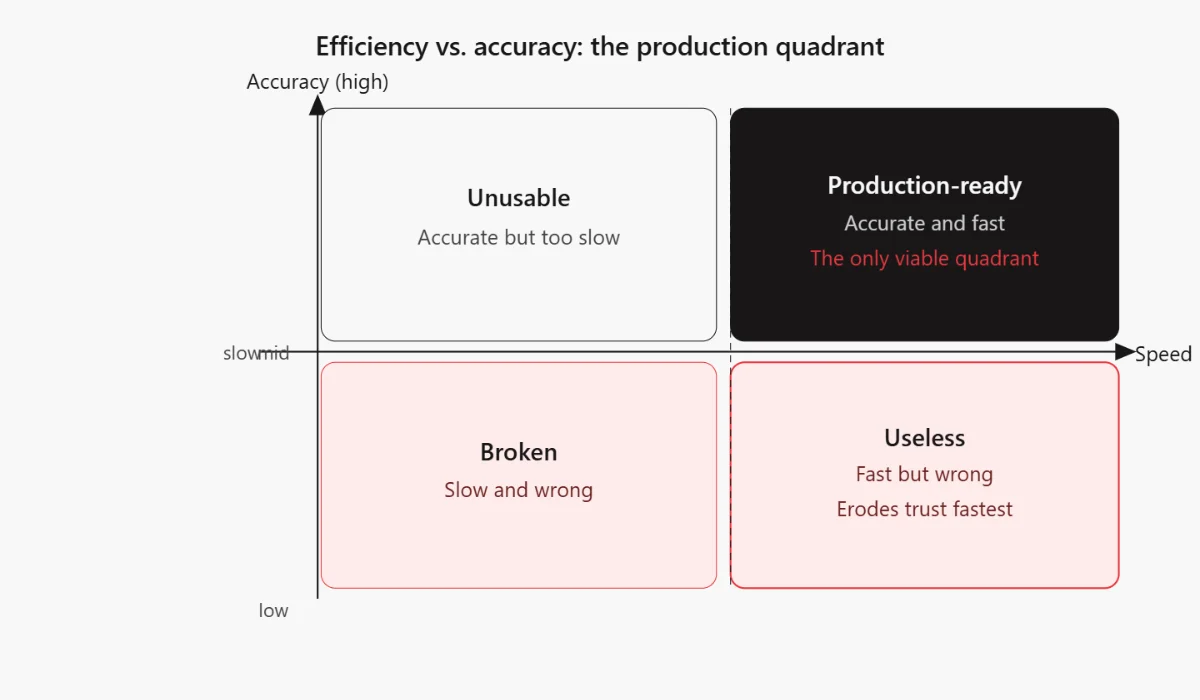
An agent that works brilliantly but takes three minutes per query or burns through your API budget isn’t production ready. Efficiency metrics keep performance grounded in economic reality.
- Latency (Response Time): How long does the agent take to respond or complete a task? Measure both average and p95 latency, outliers matter in production.
- Token Usage / Cost Per Task: Every LLM call has a cost. Track token consumption per task to understand your per-unit economics and catch runaway agent loops early.
- Steps Per Task: How many actions does the agent take to finish a job? Fewer steps, when the outcome is the same, usually means a better-designed agent.
Fast but wrong = useless. Accurate but slow = unusable. Efficiency metrics only matter when paired with task success metrics, always read them together.
Reasoning & Decision Quality Metrics
This is where AI agent evaluation gets interesting and where most generic measurement guides stop short.
Agents don’t just retrieve information. They reason, they decide which tool to use, how to interpret an ambiguous instruction, and when to ask for clarification. Measuring that reasoning is harder than measuring outputs, but it’s not impossible.
- Tool Selection Accuracy: Did the agent call the right tool for the right situation? An agent that queries a database when it should call a calendar API is making a reasoning error, even if the output looks plausible.
- Hallucination Rate: How often does the agent assert something that is factually incorrect or fabricated? This is especially critical for agents operating in regulated industries or accessing sensitive data.
- Instruction Adherence: Does the agent follow its system prompt and user instructions consistently? Drift from instructions is a signal of poor prompt engineering or context window management issues.
- Chain-of-Thought Correctness: You often can’t measure reasoning directly, but you can infer it by auditing agent traces and checking whether intermediate steps are logically sound.
Reliability & Robustness Metrics
For enterprise adoption, reliability isn’t a nice-to-have. It’s the minimum bar. An agent that works 90% of the time and fails silently the other 10% will erode trust faster than any accuracy metric can rebuild it.
- Failure Rate: What percentage of tasks end in an unrecoverable error or agent abandonment?
- Retry Rate: How often does the agent attempt the same action multiple times? High retries rates signal poor error handling or tool instability.
- Error Recovery Success: When something goes wrong mid-task, can the agent recover gracefully and complete the workflow, or does it stall?
- Consistency Across Runs: Run the same task multiple times with the same inputs. Does the agent produce consistent outputs? High variance is a red flag for production use.
Also Read: How to Test an AI Agent: Checklist & Evaluation Guide
Tool Usage & Integration Metrics
Most enterprise agents don’t just generate text, they invoke APIs, query databases, write to external systems, and interact with third-party services. These integrations deserve their own measurement layer, and this is the area most generic agent evaluations miss entirely.
- API Call Success Rate: What percentage of external API calls complete successfully? Track by tool type to identify which integrations are creating bottlenecks.
- Correct Tool Invocation: Did the agent call the right tool with the right parameters? An agent that calls the right tool with malformed inputs will fail silently in ways that are hard to debug.
- External System Accuracy: When the agent writes to or reads from an external system, a CRM, a ticketing system, a database, is the data accurate and correctly formatted?
Tool failures are often infrastructure problems disguised as agent problems. Separating tool metrics from agent metrics helps you assign accountability correctly.
User-Centric Metrics: The Ones Leadership Actually Cares About
Technical AI agent metrics tell you how the agent is performing. Business metrics tell you whether it is creating value. Both matter, but when you’re presenting to leadership or justifying investment, the second category is the one that lands.
- User Satisfaction (CSAT): Direct feedback from users who interacted with the agent. Simple post-interaction surveys capture this effectively.
- Task Abandonment Rate: How often do users give up mid-interaction? High abandonment is a signal that the agent is failing to meet expectations, even if technical metrics look healthy.
- Time Saved: How much time does the agent save compared to the manual baseline? This is often the clearest ROI signal for internal automation agents.
- Human Intervention Rate: How often does a human need to step in to correct or complete what the agent started? A declining intervention rate, over time, is one of the best indicators that your agent is genuinely improving.
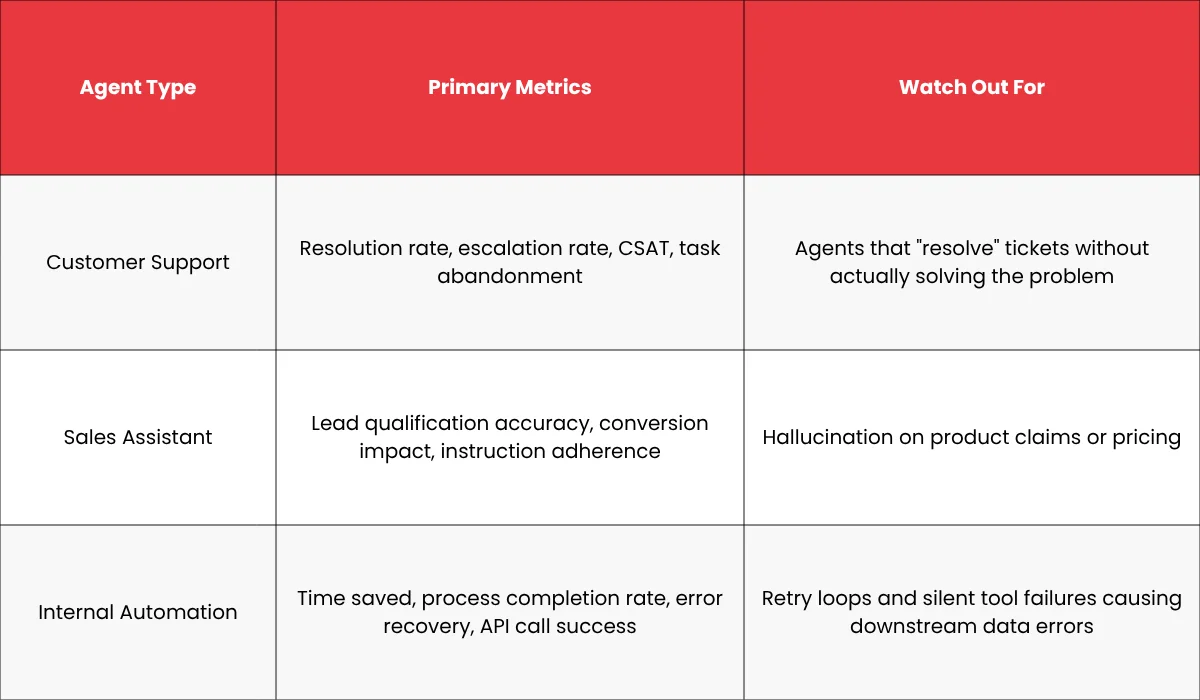
Which AI Agent Performance Metrics is Right for Your Use Case
Not all agents should be measured the same way. Here are the metrics that matter most by use case:
Common Mistakes When Measuring AI Agent Performance
Even teams that care about measurement often make these mistakes:
- Over-relying on accuracy: A high accuracy rate on test sets does not translate to production performance. Always evaluate AI agent performance on real-world data from live deployments.
- Ignoring production data: Evaluation pipelines that only run on curated benchmarks will miss the weird edge cases that actually occur in the wild. Log everything; sample aggressively.
- No human-in-the-loop evaluation: Automated metrics catch a lot, but they miss subtle reasoning failures, tone problems, and context errors. Build regular human review into your evaluation process.
- Measuring components, not workflows: Evaluating each tool call in isolation will tell you each piece works. It won’t tell you whether the agent assembles them correctly to complete an end-to-end task. Measure workflows, not parts.
AI Agent Evaluation Tools & Approaches
You don’t need to build your evaluation infrastructure from scratch. Several purpose-built platforms exist:
- LangSmith (by LangChain): Excellent for tracing multi-step agent runs, capturing tool calls, and running evaluations on agent traces. A natural fit if you’re building on LangChain.
- Arize AI: Strong on production monitoring,drift detection, performance degradation alerts, and embedding visualizations for understanding where agents are going wrong.
- Weights & Biases (W&B): Primarily known for model training, but its Weave product is increasingly used for LLM and agent evaluation, with support for logging prompts, responses, and custom metrics.
- Braintrust: Purpose-built for LLM evaluation with a clean interface for running evals, scoring outputs, and comparing prompt versions side by side.
- Human Review Loops: No tool replaces structured human review. Build a process where sampled agent interactions are reviewed by domain experts on a regular cadence, weekly at minimum.
- A/B Testing: When testing agent versions or prompt changes, run both variants in parallel with real users and compare outcome metrics, not just automated scores.
From Metrics to Improvement: Closing the Loop
AI agent performance metrics are only valuable if they drive action. The goal isn’t a dashboard, it’s a feedback loop.
- Measure: Collect data across all five pillars, in production, continuously.
- Diagnose: When a metric degrades, trace it back. Is it a prompt issue? A tool failure? A reasoning error? Agent traces are your best debugging tool.
- Improve: Make targeted changes to prompts, tool configurations, retrieval systems, or workflow logic based on what the diagnosis reveals.
- Re-evaluate: Rerun your evaluation suite after changes. Make sure you haven’t fixed one metric by breaking another.
Final Thoughts: Measuring What Actually Matters
AI agents are not judged by how impressive their underlying model is. They are judged by whether they reliably complete real tasks, in real conditions, for real users.
That means your measurement framework needs to reflect the full picture: task outcomes, efficiency, reasoning quality, robustness, tool performance, and business impact. No single metric tells everything but the five-pillar AI agent evaluation framework does. Start with task success and user impact, those are the metrics that tell you whether your agent is worth deploying. Then build out the technical layers. And always, always tie your numbers back to real-world outcomes.
The question isn’t “Is this agent accurate?” It’s “Is this agent useful?” Build your metrics to answer the second question.
FAQ
How do you evaluate an AI agent?
Evaluate agents across five dimensions: task success, efficiency, reasoning quality, reliability, and user impact. Use a combination of automated logging, evaluation pipelines, and regular human review of sampled agent traces.
What is task success rate in AI agents?
Task success rate is the percentage of assigned tasks that an agent completes end-to-end, achieving the intended goal without human intervention. It is different from task completion rate, which only measures whether the agent finished a workflow not whether it achieved the right outcome.
How is AI agent performance different from model evaluation?
Model evaluation typically measures a single output against a ground truth label. Agent evaluation must assess multi-step workflows, tool usage, sequential decision-making, and end-to-end outcomes, all of which require a more layered measurement approach than standard benchmarks provide.
What tools help measure AI agent performance?
LangSmith, Arize AI, Weights & Biases (Weave), and Braintrust are purpose-built for LLM and agent evaluation. These should be complemented by structured human review loops and A/B testing frameworks to capture what automated metrics miss.






