
There is a pattern that repeats itself across businesses that build AI models. A team spends months building an AI model. It performs well in testing. Leadership is confident. The model ships to production. Six months later, performance has quietly degraded, predictions are off, customers are noticing, and no one is quite sure when things started going wrong.
This is not an edge case. It is one of the most common and costly AI failures in production environments today. And it happens almost entirely because companies invest heavily in building AI models but barely invest in AI model management afterward.
Building an AI model is only the beginning. Managing it continuously is what creates long-term business value.
Why AI Models Fail After Deployment
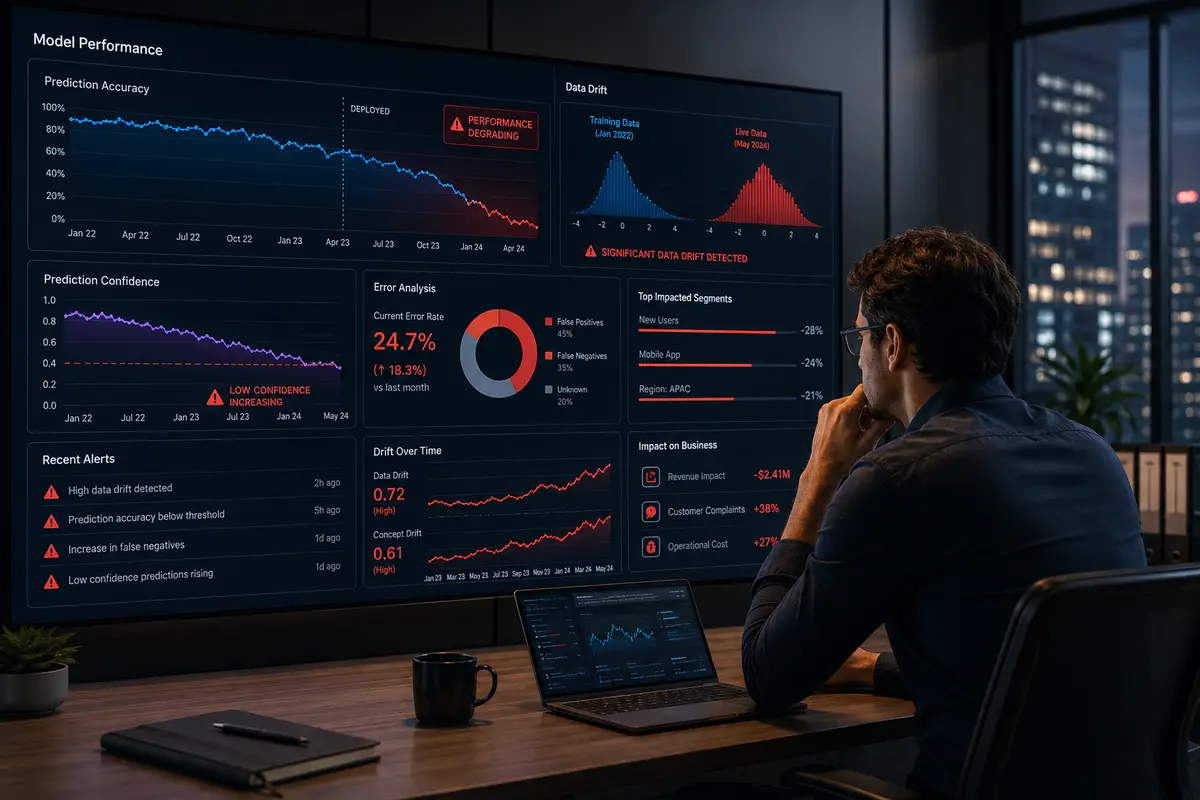
The assumption that a model, once trained and deployed, will continue performing well is one of the most expensive assumptions in AI.
Here is why AI models degrade:
- Data drift happens when the real-world data coming into your model starts looking different from the data it was trained on. A fraud detection model trained on 2022 transaction patterns will gradually fail as fraud tactics evolve in 2024 and 2025.
- Model drift (also called concept drift) happens when the relationship between your input data and the correct output changes over time, even if the data itself looks similar. Customer purchasing behavior after an economic shift is a common example. Changing user behavior means that the patterns your model learned no longer reflect how users actually interact with your product. Recommendation systems are particularly vulnerable here.
Beyond drift, common failure contributors include poor monitoring setups, biased training data that compounds over time, lack of retraining pipelines, infrastructure bottlenecks under increased load, and, critically, no clear ownership of model performance between data science and product teams.
The Hidden Cost of Poor AI Model Management

The consequences are rarely framed as “AI model management failures,” but that is what they are.
A recommendation engine that surfaces irrelevant products does not just reduce click-through rates. It erodes customer trust in the product overall. A fraud detection model that misses emerging fraud patterns does not just increase financial losses. It exposes the business to regulatory scrutiny. An AI support bot giving outdated responses does not just frustrate customers. It creates liability.
The business costs compound:
- Declining prediction accuracy leads to worse business decisions at every level that depends on those predictions
- Customer trust, once eroded by poor AI experiences, is difficult and expensive to rebuild
- Compliance and regulatory risk grow as AI governance requirements tighten globally (the EU AI Act being the clearest current example)
- Operational costs increase as teams spend more time manually fixing what automated systems should handle
- AI systems can become effectively unusable within months without proper maintenance, rendering significant development investments worthless
Most of these costs are invisible in standard AI project budgets because companies do not account for the operational phase of AI at all.
What is AI Model Management?
In practical terms, AI Model Management is the process of ensuring that your AI systems continue to perform as intended after deployment, at scale, over time.
It covers everything that happens after training: monitoring model behavior, tracking performance against real-world data, retraining when needed, managing versions, maintaining compliance, and ensuring that the infrastructure supporting the model stays reliable.
The distinction that matters most is this: training a model is a project. Operating an AI system is an ongoing responsibility.
AI Model Management sits at the intersection of MLOps, governance, monitoring, infrastructure, and business operations. It is not purely a data science concern, and it is not purely an engineering concern. It is where both disciplines meet and where most businesses
have significant gaps.
How to Manage AI Models: Key Components and Tools

Managing AI models is no longer just about training algorithms and deploying them into production. As companies scale AI across products and operations, they need systems that ensure models remain accurate, reliable, compliant, and cost-efficient over time.
Model management focuses on maintaining the entire AI model lifecycle after development. This includes monitoring AI performance, retraining models, managing infrastructure, and ensuring governance across teams.
Below are the core components that help scaling businesses keep AI models performing effectively.
1. Model Versioning and Experiment Tracking
AI teams continuously test different datasets, architectures, and training approaches. Without structured version control, it becomes difficult to reproduce results or understand which model version is performing in production.
Key functions include:
- Tracking model versions
- Comparing experiments
- Storing hyperparameters and datasets
- Enabling rollback to previous models
- Improving reproducibility across teams
Use these tools for model versioning control: MLflow, Weights & Biases, Neptune.ai
2. Continuous Monitoring and Drift Detection
AI models naturally degrade as real-world data changes. Customer behavior, market conditions, and usage patterns evolve constantly, creating performance gaps between training environments and production environments.
Monitoring systems help :
- Detect data drift
- Identify concept drift
- Track prediction accuracy
- Monitor latency and uptime
- Identify bias or anomalous outputs
- Prevent silent model failures
Tools to use: Arize AI, WhyLabs, Fiddler AI
3. Automated Retraining Pipelines
Static AI models eventually become outdated. Scaling companies automate retraining workflows to keep models aligned with fresh data and changing business conditions.
Automated retraining systems typically:
- Collect updated production data
- Retrain models on schedules or triggers
- Validate AI model quality automatically
- Redeploy improved versions
- Reduce manual operational work
Tools to use: Kubeflow, Apache Airflow, Amazon SageMaker
4. Deployment and Infrastructure Management
Deploying AI models at scale requires infrastructure that can handle real-time inference, high traffic, reliability, and operational efficiency.
Key infrastructure capabilities include:
- Scalable API deployment
- Containerized environments
- Orchestration systems
- Latency optimization
- Rollback management
- Cloud resource scaling
Tools to use: Docker, Kubernetes, TensorFlow Serving
5. Governance, Compliance, and Explainability
As AI systems influence business-critical decisions, governance becomes essential for risk management and regulatory compliance. Governance frameworks help you:
- Explain AI decisions
- Maintain audit trails
- Monitor fairness and bias
- Comply with regulations
- Manage security and access controls
- Reduce reputational risk
Tools to use: IBM Watson OpenScale, DataRobot, Azure Machine Learning
6. Centralized Model Registry and Documentation
As organizations scale AI adoption, managing multiple models across departments becomes operationally complex. Centralized registries improve visibility and coordination. Model registries help you:
- Track deployed models
- Manage ownership
- Document model lifecycle history
- Monitor deployment environments
- Improve collaboration between teams
- Standardize AI operations
Tools to use: MLflow Model Registry, Vertex AI, H2O.ai
How to Scale an AI Model
Scaling an AI model means making it capable of handling larger workloads, more users, more data, and more business use cases without losing performance, reliability, or accuracy.
Key ways to scale AI models are:
- Automating deployment pipelines: Using MLOps systems to push AI models from development to production faster and more reliably.
- Using cloud infrastructure: Running models on scalable cloud platforms that can handle increasing traffic and compute demands.
- Implementing continuous monitoring: Tracking accuracy, latency, drift, and failures in real time to maintain performance.
- Automating retraining: Regularly updating models with fresh data so predictions remain relevant as conditions change.
- Containerizing models: Using tools like Docker and Kubernetes to scale deployments efficiently across environments.
- Optimizing inference performance: Reducing response time and infrastructure costs through model compression, caching, and hardware acceleration.
- Standardizing governance: Creating centralized processes for security, compliance, versioning, and documentation as AI adoption grows.
- Building reusable AI infrastructure: Instead of creating isolated AI projects, scaling companies build shared platforms that support multiple models and teams.
Key Metrics for Keeping AI Models Healthy
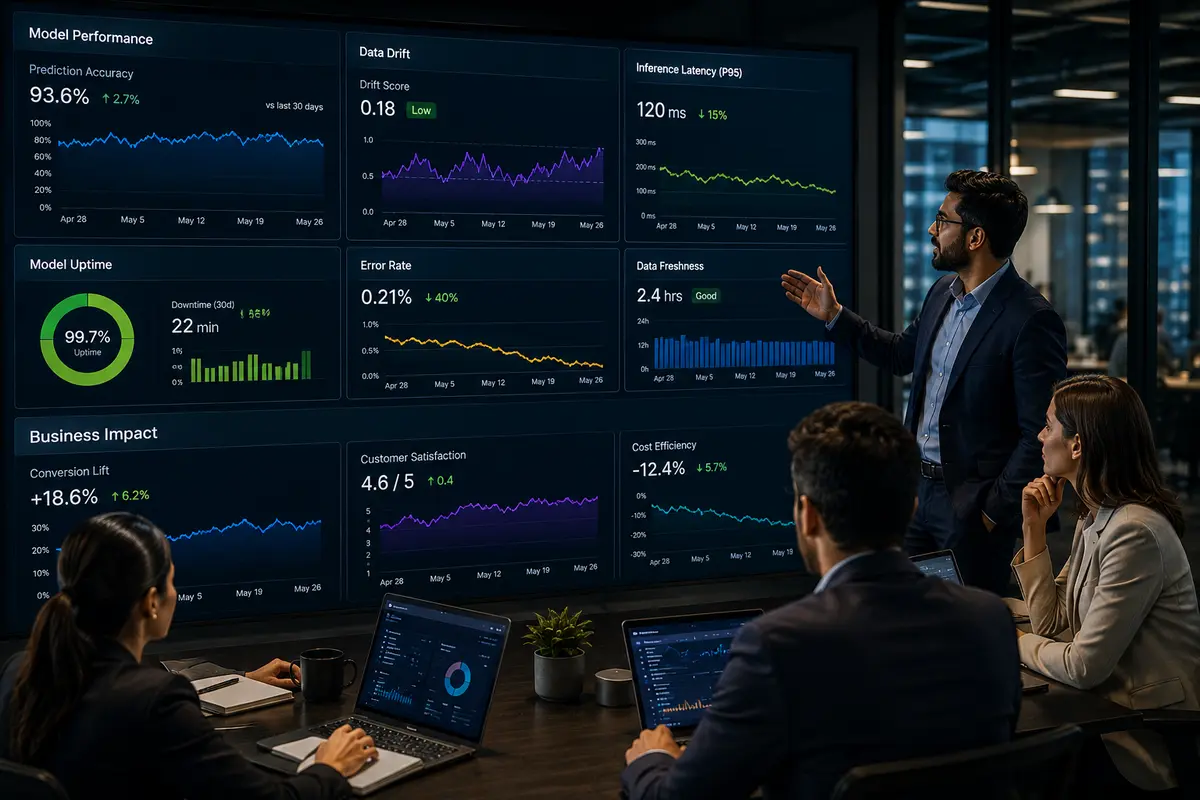
The businesses that manage AI models well track two categories of metrics simultaneously.
Technical model metrics:
- Prediction accuracy (overall correctness)
- Precision and recall (relevant for classification models, catching the right things without too many false alarms)
- Drift scores (quantifying how much input data or model behavior has shifted)
- Inference latency (response time under production load)
- Uptime and error rates
Business impact metrics:
- Revenue directly attributable to model-driven decisions
- Customer satisfaction scores for AI-powered features
- False positive/negative rates in business terms (missed fraud, incorrectly flagged transactions)
- Conversion rates for recommendation-driven experiences
The gap between technical performance and business performance is more common than most teams realize. A model can maintain high technical accuracy, while its business impact often declines because the business context has shifted in ways the technical metrics do not capture.
Common Mistakes in AI Model Management
Most of these mistakes share a common root: treating deployment as the end of the AI project rather than the beginning of AI operations.
- Treating deployment as the finish line is the most fundamental error. Shipping a model is when the real operational work begins.
- Ignoring monitoring until something breaks means you are always reactive. By the time a problem is visible without monitoring, it has usually been degrading for weeks.
- No retraining strategy means models that were built to be dynamic become static — and reality moves past them.
- Poor documentation creates operational brittleness. When the person who built the model leaves, institutional knowledge of how it works, why certain decisions were made, and what its limitations are often leaves with them.
- Siloed teams, where data science builds models and engineering deploys them with little ongoing collaboration, create accountability gaps. When performance degrades, no one is clearly responsible.
Conclusion
In the next phase of AI adoption, operational excellence in AI Model Management will separate experimental AI companies from truly AI-driven businesses. The model you shipped last year is not the model you need today. The question is whether your organization has the systems, the processes, and the discipline to keep up.
FAQs
What is AI model management?
AI model management is the process of monitoring, maintaining, updating, and governing AI models throughout their lifecycle. It helps ensure that models continue to perform accurately and reliably after deployment.
Why is AI model management important?
Managing AI models is important because their performance can degrade over time, either due to changes in data or user behavior. Proper model management helps companies prevent performance decline, reduce operational risks, and maintain business reliability.
How often should AI models be retrained?
The retraining frequency depends on how quickly data changes. Some models require weekly updates, while others may only need retraining every few months. High-volume or fast-changing industries typically retrain models more frequently.
How to scale AI models successfully?
Companies scale AI models by automating deployment, implementing monitoring systems, using cloud infrastructure, retraining models continuously, and building standardized AI operations across teams.
What are the biggest challenges in managing AI models?
The biggest challenges include maintaining model accuracy, managing infrastructure costs, handling governance requirements, monitoring drift, and coordinating between data science and engineering teams.






