
Most AI agents fail not because the technology is wrong, but because organizations skip critical steps between “it works in a demo” and “it runs in production.” Here’s the full AI agent lifecycle, and what actually matters at each stage.
There’s a pattern playing out inside organizations across every industry right now. Teams build an AI agent prototype quickly that works just fine for the start. Leadership gets excited. Budget is approved. And the prototype is put into production. Six months later, the agent fails to perform in real-world scenarios.
The problem isn’t the AI. It’s the lifecycle.
Building a reliable, scalable AI agent is an engineering and organizational discipline – one that has well-defined phases, distinct failure modes at each stage, and specific decisions that determine whether you end up with a competitive asset or an expensive proof of concept that never graduates.
This guide walks through the complete AI agent development lifecycle – the five stages every enterprise deployment goes through, what it takes to navigate each successfully, and where organizations most commonly get stuck.
The Five Stages of AI Agent Lifecycle
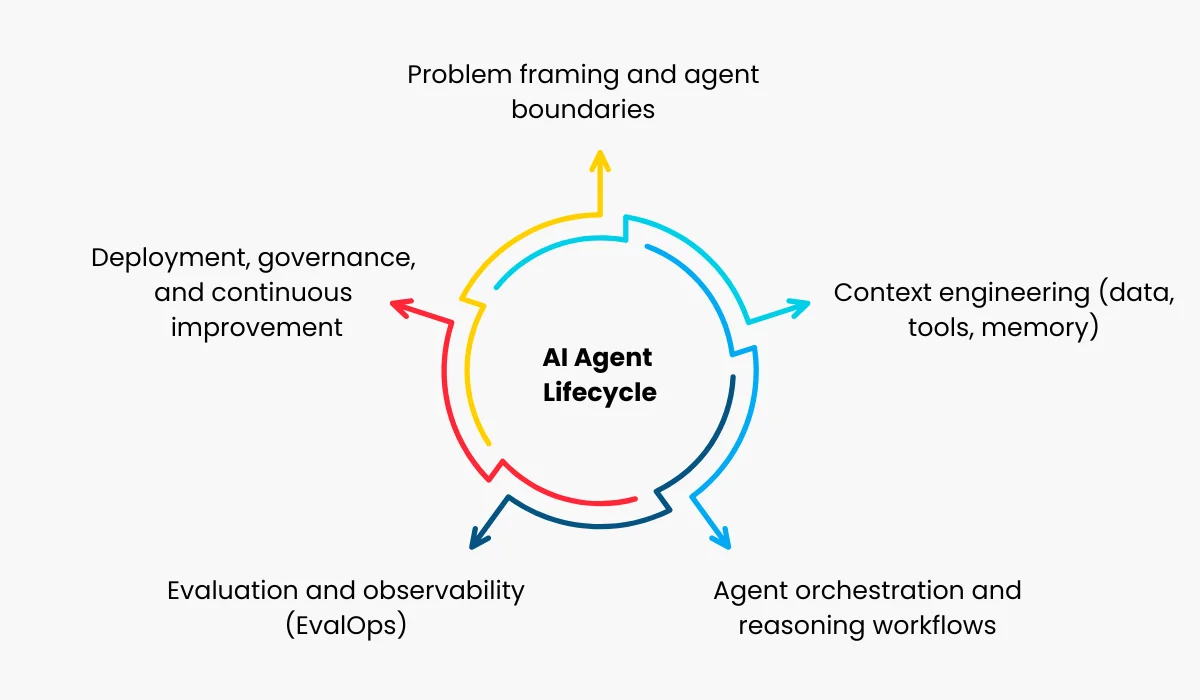
Stage 01: Problem Definition & Feasibility
The most consequential phase of the agent lifecycle happens before a single line of code is written. This is where organizations define the specific, bounded problem the agent will solve, and it requires more discipline than most teams expect.
AI agents perform best when operating in a well-defined domain with clear success criteria. The mistake most organizations make is starting with the technology (“let’s build an AI agent”) rather than the workflow (“here is a specific, high-value task that currently takes 40 analyst hours per week and has clear inputs and outputs”).
What to Define Before You Build
Before any prototype begins, you need answers to: What exactly is the agent deciding or doing? Systems that it would access for the given role? What does a correct output look like, and who judges correctness? What happens when it fails? How will you measure success at scale?
Feasibility assessment at this stage includes evaluating data availability, tool and API access requirements, latency constraints, and whether the task is actually automatable with current AI capabilities. Skipping this creates a prototype that passes a demo but breaks the moment it meets real-world data.
- Specific business task defined with measurable outcomes
- Data sources, APIs, and tool access mapped
- Success criteria and evaluation method established
- Failure modes and fallback behaviors defined
- Compliance and regulatory requirements identified
Stage 02: Prototype & Validate
The prototype phase has one purpose: prove the core AI capability works on real data, in real conditions. Nothing more.
This is where teams build a minimal, working version of the agent- connecting it to actual data sources, testing it on real inputs, and evaluating outputs against the success criteria defined in Stage 1. The prototype should be quick, deliberate, and aggressively scoped.
The most common mistake is building too much. Teams keep on adding new features, improving the user interface, connecting to more systems, and expanding the scope. A prototype should answer one question: Can this agent work well post-production?

Validation is another important thing at this stage. You need an AI agent evaluation framework: a representative test set, a scoring rubric, and a threshold that indicates whether the agent is ready to move forward.
Without it, “it looks good” becomes the de facto bar, and you will discover the gaps in production.
Stage 03: Pilot Deployment
The pilot phase is where prototypes most frequently collapse and where the gap between “it works” and “it works reliably” becomes undeniable.
A pilot means deploying the agent to a real, limited-production environment: real users, real data, real edge cases, but with a contained scope and active human oversight. The goals are to surface failure modes that didn’t appear in testing, build organizational trust in the agent, and gather the performance data needed to make a go/no-go decision on full deployment.
Critical at this stage: Human-in-the-loop review
All agent outputs should go through human review during the pilot. This isn’t a sign of failure; it’s how you catch edge cases before they become incidents and build the confidence needed for autonomous operation.
Best Practice
- Watch for Hallucination and reasoning errors
Real-world data is messier than test data. Pilots consistently surface inputs that the agent was never intended to handle. Log every failure, categorize it, and build remediation into the roadmap.
- Watch for Integration fragility
API timeouts, schema changes, authentication failures, and rate limits all surface during pilots. If integrations aren’t robust, the agent’s reliability ceiling is set by its most fragile dependency.
- Build Feedback loops and logging
Every interaction should be logged, reviewable, and fed back into agent improvement. Pilots that don’t generate structured feedback data are missed opportunities for compounding improvement.
A successful pilot doesn’t mean zero errors; it means you have a clear picture of error rates, error types, and a credible path to addressing them. Decision-makers should receive a structured report from the pilot: performance metrics, failure categorization, user feedback, cost-per-transaction, and a recommendation on whether and how to proceed.
Also Read: Enterprise AI Agent Architecture
Stage 04: Scale & Harden

This is the engineering-heavy phase. The agent has been proven in a limited environment. Now it needs to run at scale, which exposes an entirely different set of requirements for reliability, security, performance, and cost.
Hardening an AI agent for enterprise deployment means building in the properties that production systems require but that demos and pilots rarely address.
- Fault tolerance and graceful degradation
The agent needs defined behavior when its tools, APIs, or underlying models fail. What does it do when it can’t complete a task? Fallback logic, error escalation paths, and retry strategies should be engineered, not improvised.
- Security and access control
Enterprise agents access sensitive systems. Role-based access, audit trails, data handling policies, and integration with your security infrastructure need to be designed and validated, not retrofitted after deployment.
- Latency and cost optimization
Model inference costs and latency at scale are materially different from prototype costs. Caching strategies, prompt engineering for efficiency, AI model selection based on task complexity, and batching logic all determine whether the agent is economically sustainable at scale.
- Compliance and auditability
Regulated industries require that every agent’s decision is explainable, logged, and auditable. Build this in now. Retrofitting auditability is one of the most expensive mistakes in the deployment of enterprise AI agents.
- Load testing and capacity planning
Run the agent under a realistic load before full deployment. Identify throughput ceilings, model rate limit bottlenecks, and infrastructure scaling requirements. Surprises at this stage are expensive. Surprises in production are worse.
Also Read: Single AI Agent vs. Multi-Agent AI Systems Architecture Comparison
Stage 05: Monitor, Evaluate & Optimize
![]()
An AI agent deployed without a monitoring strategy begins to degrade silently in production and often goes undetected until the impact is significant.
Models drift. Data distributions shift. Business rules change. Tools and APIs get updated. What worked on Day 1 may be producing subtly different outputs on Day 90, and without active monitoring, nobody knows until something breaks visibly.
“Monitoring AI agents under production should be a continuous process to ensure a deployed agent will work under all business conditions, and produce reliable outcomes over time.”
AI agent lifecycle management covers several distinct layers: output quality (are the answers still correct?), operational health (latency, error rates, uptime), cost efficiency (cost per successful completion), and business impact (is the agent actually delivering the outcomes it was built for?).
Beyond monitoring and agent management, Stage 5 is where agents improve. Every logged interaction is a training signal. Patterns in failures reveal capability gaps. User feedback surfaces edge cases that the original design didn’t account for. Organizations that build structured improvement cycles into this stage compound their ROI over time – the agent gets better, faster, and more cost-efficient as it matures.
The Compounding Advantage
Organizations that treat Stage 5 as an ongoing investment rather than a maintenance cost consistently outperform those that don’t. The improvement cycle compounds: better monitoring enables faster iteration, faster iteration improves quality, and higher quality builds the organizational trust that unlocks broader deployment and greater ROI.
The AI Agent Development Lifecycle Is the Strategy

The question most decision-makers ask about AI agents is: “Will this work?” The better question is: “Do we have a process for making this work reliably, at scale, and sustainably?”
The five-stage AI agent lifecycle described here is not a theoretical framework. It defines what separates enterprise AI agent deployment from pilots that stall, prototypes that never ship, and investments that fail to justify themselves.
Each stage has clear inputs, clear outputs, and clear gates that determine whether you’re ready to move forward. Organizations that respect these gates move faster because they avoid the rework, production incidents, and trust deficits that come from skipping them. A strong generative AI strategy also plays a critical role in ensuring AI agents are scalable, reliable, and aligned with long-term business objectives.
The organizations winning with AI agents right now aren’t necessarily the ones with the most advanced models. They’re the ones with the most disciplined lifecycle.
Our team has guided enterprise AI agent deployments across healthcare, financial services, operations, and technology. Let’s talk about where you are in the AI agent lifecycle and what it takes to move forward.
Contact Our Team. No pitch decks. Just a direct conversation about your use case.






