
In today’s digital world, if your app/software or service is down for a second, you’re losing customers, money, and reputation. Every tech company faces a core challenge: how do we launch new features faster and faster, but still keep everything rock-solid stable?
The answer, an approach first developed at Google and now used everywhere, is Site Reliability Engineering (SRE).
SRE isn’t just a title. It’s a disciplined, smart way of running your production systems by treating operations like a software problem. It moves the job of keeping things running from manual firefighting to clever engineering. This allows teams to scale their systems and deliver products faster without the inevitable crashes and engineer burnout that traditional models cause.
This guide will break down the most important questions- what is SRE, how it improves software uptime and reduces downtime incidents, best and the practical steps you can take to implement it.
What is Site Reliability Engineering?

At its heart, Site Reliability Engineering (SRE) is about using software engineering to solve operations problems.
SRE was created out of necessity at Google in the early 2000s. Their systems were growing so fast that traditional operations teams (often called Sysadmins) couldn’t keep up. The old way relied on manual, time-consuming, and error-prone fixes.
The core idea is simple: if you have a repetitive operational task like managing servers, deploying code, or checking system health, don’t just do it manually. Write code to automate it. An SRE is a software engineer whose sole focus is making systems reliable, scalable, and efficient. By automating “toil” (the manual, boring work), SREs ensure engineers spend their time building permanent solutions instead of constantly putting out fires.
What Does a Site Reliability Engineer Do?
An SRE is a true hybrid, blending deep software development skills with expertise in systems and infrastructure. A site reliability engineer’s main mission is to make sure your service consistently hits its reliability targets.
Daily Responsibilities and Common Tasks:
- Automation is Priority #1: They write code (often in Python, Go, or Java) to automate everything from server setup and security patching to deployment. If they have to do a task twice, they automate it.
- Monitoring and Observability: They design and maintain the tools (monitoring, logging, tracing) that give teams clear visibility into service health. They define the metrics that tell you what’s actually happening.
- Incident Response: They are on-call to quickly jump in and fix production issues. Their focus is on minimizing downtime and making sure communication is clear and fast during an outage.
- Capacity Planning: They work with product teams to forecast future traffic and ensure the infrastructure can handle anticipated growth without crashing.
- Deployment Pipeline: They build the Continuous Integration/Continuous Delivery (CI/CD) pipelines to guarantee releases are fast, automated, and reliable.
How SRE is Different From Sysadmins and DevOps Engineers
A traditional Sysadmin mostly manages systems through manual configurations. DevOps is a philosophy about culture and collaboration between Dev and Ops. SRE is the practical blueprint for implementing DevOps. SRE focuses specifically on measuring reliability (using SLOs) and using code as the main tool to achieve operational excellence.
What are the Core Pillars of SRE?
While SRE is flexible, most successful programs rely on four fundamental pillars that guide every decision and strategy. We can think of them as: Availability, Performance, Monitoring, and Incident Response.
- Availability: It means the system is running when users need it. This is defined by a clear target, called a Service Level Objective (SLO), and is often expressed as “nines” (e.g., 99.99% availability).
- Performance: This measures how fast and efficiently the system responds. If a system is too slow (high latency), users will leave, making it feel broken even if it’s technically “up.”
- Monitoring & Observability: You can’t fix what you can’t see. This pillar is about setting up the right tools (logging, metrics, tracing) to get deep, actionable insight into the system’s behavior. This lets teams catch minor issues before they become major outages.
- Incident Response: This is your plan for when things go wrong. It means having documented procedures (runbooks), clear communication plans, and the ability to execute a fast, efficient fix to minimize the impact of any failure.
These four areas of SRE work together. For instance, strong Monitoring allows you to meet your Availability goals and execute effective Incident Response.
What is SRE in DevOps?
SRE acts as the essential “safety net” for the high-speed delivery environment that DevOps creates. Without SRE, the push for constant releases (a key DevOps goal) would quickly lead to disastrous instability.
SRE supports the DevOps culture by:
- Engineering Reliability: SRE treats reliability as a mandatory feature that must be built, measured, and funded, instead of just hoping for stability later.
- Using Data to Quantify Risk: Through Service Level Objectives (SLOs) and Error Budgets, SRE gives Dev teams a clear, data-driven limit. If they introduce too many errors and spend their monthly error budget, releases must stop. This makes reliability non-negotiable.
- Building the Right Tools: SREs are the experts who write the software tools, create Infrastructure-as-Code (IaC) templates, and automate pipelines that Dev teams then use, turning the DevOps goal of shared responsibility into practical reality.
Is SRE Better Than DevOps?

This is a trick question. SRE isn’t better than DevOps; it’s how you actually do DevOps.
DevOps is the goal. It’s the philosophy of tearing down the wall between developers and operations teams, increasing automation, and moving faster. It focuses on the cultural shift.
SRE is the method. It’s the specific set of practices, roles, and measurements used to achieve the reliability and speed goals of DevOps. It introduces the Error Budget as a quantitative rule to make sure speed never breaks stability.
How to think about SRE vs. DevOps:
- DevOps: The What (The company wants to collaborate and deliver value faster).
- SRE: The How (The SRE team uses code and SLOs to make that collaboration and speed sustainable).
- Both: The vast majority of top-tier companies adopt the DevOps culture and use SRE practices to keep their systems reliable at scale.
What are the SRE Best Practices?
There are several key, repeatable, and best SRE practices that help engineering teams work and make decisions.
- Service Level Indicators (SLIs) and Objectives (SLOs): These define success.
- SLI: A measurable signal of how your service is performing from the customer’s point of view (e.g., how often requests succeed, how fast the page loads).
- SLO: The specific target you promise to hit for that SLI (e.g., 99.9% of user requests must complete in under 300ms).
- Error Budgets: This is the small amount of acceptable failure you allow, calculated as 100% minus your SLO. This budget is key: if the budget is spent (meaning too many errors occurred), the development team must pause feature work and focus on stability until the budget is replenished.
- Automation-First Mindset: The goal is to eliminate manual work entirely. SRE teams typically aim to spend 50% of their time on engineering (automation) and no more than 50% on operations (toil).
- Blameless Postmortems: After a major incident, the team performs a review focused only on understanding what went wrong in the system and why—never who was responsible. The goal is to find concrete actions to prevent the issue from happening again.
- Runbooks and Playbooks: Detailed, documented instructions for resolving common issues (runbooks) and managing large, complex incidents (playbooks). This prevents crisis panic and ensures a standardized, effective response.
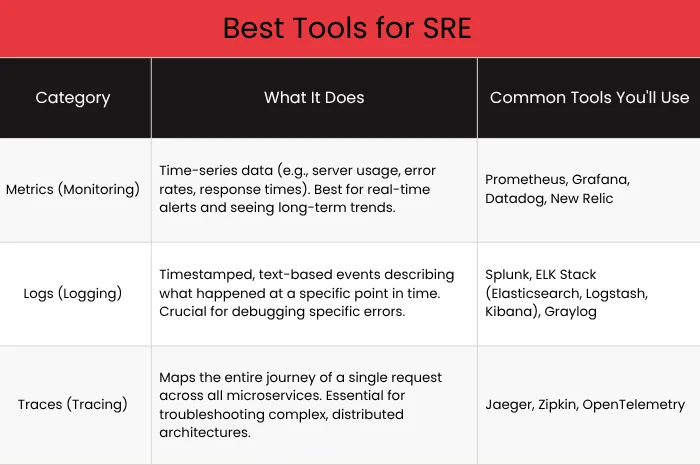
What are the Best SRE Monitoring Tools?
Site reliability relies heavily on observability, which means collecting and analyzing three types of data to understand the health of your system. These tools for SRE help in understanding that data.
How to Choose SRE Tools:
Look for solutions that:
- Integrate Widely: Can they pull data from every part of your infrastructure (cloud, containers, on-prem)?
- Handle Scale: Can they manage the massive volume of data your systems generate as you grow?
- Correlate Data: Can you easily jump from a metric alert to the specific logs or traces that explain the root cause?
What are the Key Benefits of SRE Implementation?
Adopting SRE isn’t just about playing defense; it’s a powerful strategy that drives business growth and stability. Here are a few benefits of implementing SRE.
- Fewer Outages, Higher Availability: By setting clear SLOs and using data to find weaknesses proactively, SRE teams reduce both the frequency and duration of downtime.
- Faster, Safer Feature Launches: The Error Budget system means Dev teams can move quickly, knowing there’s a guardrail. Automation makes the entire deployment process safer, allowing for more frequent releases.
- Happier Customers (Better UX): A reliable, fast-performing service builds trust. Consistently meeting your SLOs directly translates into customer loyalty and satisfaction.
- Data-Driven Decisions: SRE replaces guesswork with measurable reality. All key engineering decisions, from funding infrastructure to paying down technical debt, are guided by objective SLI/SLO metrics.
- Reduced Burnout and Higher Efficiency: Automation eliminates manual toil. This frees up your expensive, highly skilled engineers to focus on innovation and long-term stability projects, rather than simply fighting the same fires every day.
How Does SRE Help Reduce Incidents and Downtime?

Using SRE best practices for uptime and scalability is crucial because downtime can happen anytime. Site reliability engineers attack the problem of downtime with a disciplined cycle of prevention, rapid reaction, and continuous learning.
- Proactive Monitoring: SRE teams set up alerts based on symptoms (what the user experiences, like errors or slow loading) rather than causes (like high CPU usage). This lets them detect degradation early, often before the user even notices a problem.
- Automation is the First Responder: For known issues, SREs build automated remediation scripts. These scripts can often fix minor issues without any human involvement, stopping downtime before it even starts and eliminating human error in a crisis.
- Structured Incident Response: When a major issue hits, defined playbooks and communication protocols ensure the response is calm, coordinated, and efficient. This dramatically cuts down on the Mean Time to Resolution (MTTR).
- The Learning Loop: The blameless postmortem ensures that every outage, big or small, results in an action item. These learnings are immediately integrated into the system, preventing the same type of failure from ever happening again.
Why is SRE Important?
While the immediate benefits of SRE are technical like reducing downtime, its true value lies in its strategic impact on the business. SRE fundamentally changes the relationship between reliability and innovation, turning the former into a key enabler of the latter.
SRE ensures that your engineering resources are invested wisely:
- Managing Risk vs. Velocity: The Error Budget is the clearest signal you have for managing business risk. When the budget is nearly spent, the system literally tells leadership, “Stop deploying features; focus on quality.” This prevents catastrophic failures that erode user trust and cause long-term brand damage.
- Predictable Scaling: SRE provides the framework for predictable growth. Instead of scrambling to fix infrastructure after a major traffic spike (reactive scaling), SRE capacity planning and automation ensure your resources scale reliably ahead of demand, providing a seamless experience for users as your business expands.
- Protecting Brand Reputation: In the age of constant connectivity, reliability is a key product feature. If your competitor offers a faster, more reliable service, customers will leave. SRE ensures your service consistently meets the high standard of performance necessary to maintain a competitive edge and protect your brand’s reputation.
What are the 4 Golden Rules of SRE?
These four rules capture the spirit of the SRE mindset and guide every decision your team makes:
- Embrace Risk (Aim for the SLO, Not 100%): Perfect reliability (100%) is too expensive and rarely necessary. The goal is to hit the SLO, which is the reliability target the business needs. The Error Budget is the tool that quantifies and manages this acceptable risk.
- Focus on the Goal (Reliability is Currency): SRE work should always prioritize activities that protect the SLO- building automation, improving monitoring, and fixing the root causes of instability.
- Automate Everything: If you have to do it by hand, you’re doing it wrong. Automation is the only way to scale your operations without increasing your team size or introducing human error. A core SRE principle is: “A human should never have to manually touch a production system.”
- Measure Everything: All decisions must be based on data. This means defining and tracking SLIs, measuring your MTTR, measuring toil, and tracking usage. If you can’t measure it accurately, you can’t manage it effectively.
Conclusion
Site Reliability Engineering is the evolution of the operational model. It takes the goodwill and culture of DevOps and adds the critical layer of engineering discipline needed to run complex, modern systems.
If your development teams are constantly slowed down by instability, if your engineers are suffering from constant emergency calls, or if your service availability is falling short of customer expectations, site reliability engineering is your solution.






