
Chatbots have come a long way from giving robotic, pre-scripted replies. Thanks to powerful AI models like ChatGPT, chatbot performance has significantly improved—they can now hold engaging, human-like conversations, solve complex problems, generate creative content, and even write clean, functioning code.
But despite this impressive intelligence, there is a hidden constraint that quietly shapes everything a chatbot can do: AI token limits.
If your chatbot forgets earlier messages, gives incomplete answers, or suddenly starts acting confused, it is likely brushing up against this invisible ceiling. In this blog, we will demystify what tokens are, why GPT token limits exist, and how they directly affect your chatbot’s real-world performance, plus how to work around them smartly.
What Are Chatbot Tokens?

Think of tokens as the tiniest building blocks of text that an AI model can interpret, like puzzle pieces of language. However, they do not always align perfectly with individual words.
A token can be:
- A whole word (“chat”)
- A subword (“unbelievable” = “un” + “believ” + “able”)
- A punctuation mark or even a space
Quick breakdown:
- 1 token ≈ 4 characters of text
- 75 words ≈ 100 tokens
- A 1,000-word document ≈ 1,300–1,500 tokens
Every interaction with the chatbot- the input, output, and memory of previous messages- consumes tokens.
What Are GPT Token Limits?
Every AI model has a maximum number of tokens it can handle in a single operation. This includes:
- Your message
- The chatbot’s response
- Previous conversation history
- Any system instructions or background prompts
Here are the token limits for some OpenAI models:
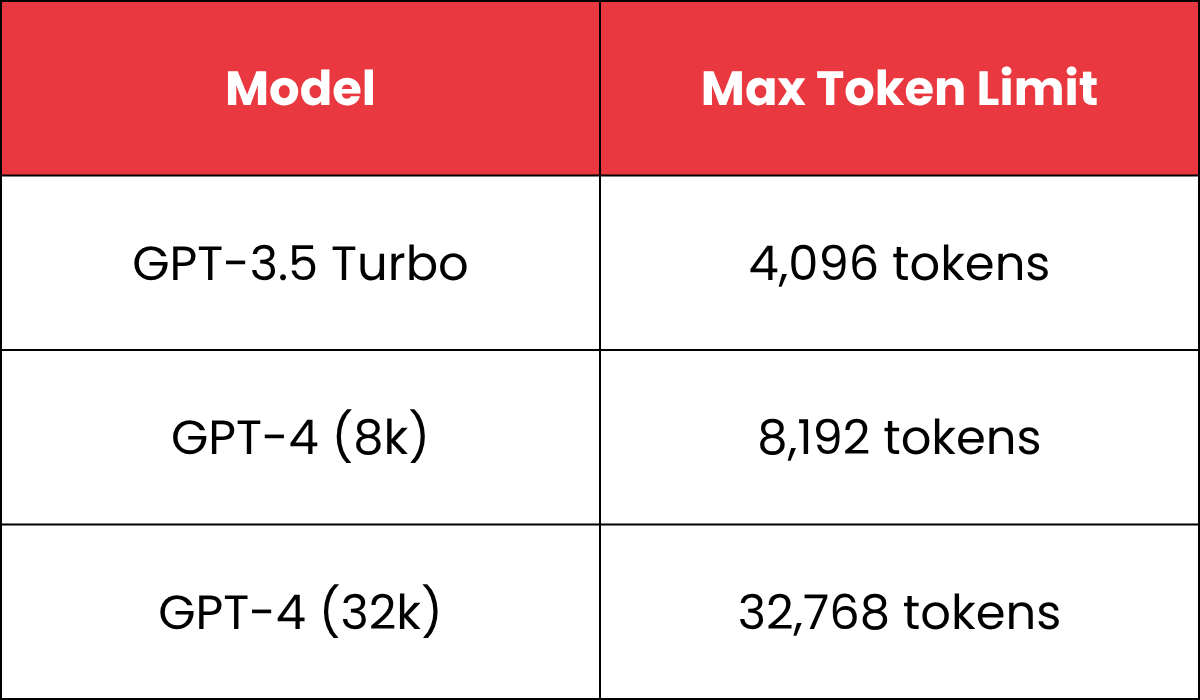
Once this limit is reached, the model forgets older context or cuts off its reply, and that is where performance begins to suffer.
How AI Tokens Differ from Traditional Tokenization
In classic NLP (such as spaCy or NLTK), “tokens” are typically whole words, split based on spaces and punctuation. But AI models like GPT use a different method (like Byte Pair Encoding) to break text into smaller, compressed units for better performance and cross-language support.
Example Comparison: NLP vs. GPT Tokenization
Text: “unbelievable”
NLP Tokens: [“unbelievable”]
GPT Tokens: [“un”, “believ”, “able”]
Text: “ChatGPT is smart.”
NLP Tokens: [“ChatGPT”, “is”, “smart”]
GPT Tokens: [“Chat”, “G”, “PT”, ” is”, ” smart”, “.”]
How to See Tokens in Action
You can test how a model breaks your text into tokens using OpenAI’s Tokenizer Tool. Just paste any sentence and see how many tokens it consumes; you’ll often be surprised!
Why This Matters
Misunderstanding chatbot tokens leads to:
- Unexpected chatbot cut-offs
- Losing memory of earlier messages
- Poor prompt design (using too many tokens)
By understanding how tokens work, you can better manage performance, cost, and UX in any AI-driven app.
How Token Limits Impact Chatbot Performance

Now, let’s break it down further: here is how token limits impact chatbot performance:
1. Loss of Context in Long Conversations
One of the biggest strengths of AI chatbots is their memory of earlier parts of the conversation, but token limits can break that illusion. When the token limit is reached, the model quietly discards the earlier parts of the conversation.
Real-World Example:
Imagine you have walked a customer through 10 steps of troubleshooting. On step 11, the chatbot suggests starting over, forgetting everything done earlier, because the first few messages have been cut off to make room for new ones.
Impact:
- Chatbot forgets names, preferences, or key instructions
- Conversations feel repetitive or disconnected
- Users get frustrated with irrelevant or outdated answers
2. Truncated or Incomplete Responses
When your input uses up most of the token budget, there is not enough space left for the model to reply properly. It may:
- Stop mid-sentence
- Miss key points
- Fail to complete lists, code, or explanations
Real-World Example:
You paste a long 1,000-word article asking for a summary, but only receive a paragraph, because there was not enough room left for a detailed reply.
Impact:
- Partial or confusing answers
- Poor summaries and explanations
- Users needing to rephrase or shorten their queries
3. Decreased Accuracy and Relevance
As token usage nears the limit, the model has to work with a smaller window of context. It may ignore older but important messages and rely only on the most recent ones.
Real-World Example:
You shared your budget and marketing goals earlier, but when asking for campaign ideas, the chatbot suggests something completely off-target, because that info is no longer in its memory.
Impact:
- Poor follow-up responses
- Inconsistent or off-topic answers
- Reduced personalization
4. Limitations on Complex Tasks
Some use cases- like analyzing legal documents, diagnosing medical records, or forecasting financial trends- involve large volumes of input. But token limits mean the model can not digest everything at once.
Real-World Example:
You are developing a legal assistant chatbot designed to analyze and interpret contracts. A full 30-page document exceeds the model’s token limit, so only a portion is processed, and critical clauses may be overlooked.
Impact:
- Tasks must be broken into smaller chunks manually
- Higher risk of missing crucial details
- Reduced efficiency and accuracy for high-stakes tasks
How to Work Around Chatbot Token Limits

Though you can not remove token limits, you can outsmart them. Here is how:
1. Keep Inputs Concise
The shorter your prompt, the more space the model has to generate a response.
Instead of:
“I am looking for a detailed explanation on how search engine optimization works…”
Try:
“Briefly explain on-page SEO.”
2. Summarize Past Conversations
Instead of repeating everything, summarize key context in a sentence:
“So far, we have discussed churn and retention. Now suggest UI fixes.”
3. Use External Memory (for Developers)
In production apps, use external storage (databases or vector stores) to remember key facts. Inject only relevant info into the prompt to avoid overloading the model.
4. Break Down Large Tasks
Split long documents or tasks into smaller parts. Process them in sequence and then combine the outputs- this modular approach is more scalable and accurate.
5. Choose Models with Higher Token Limits
For longer or more complex conversations, use models like GPT-4-32k or Claude 2 that can handle larger context windows and yield better performance.
Use Case Snapshot: Token Limits in Action
Scenario: A chatbot for insurance support.
Problem: A customer shares policy details, claim info, and medical documents over 10+ messages. At some point, the chatbot forgets the policy number.
Cause: Token limit exceeded- older messages were discarded from chatbot memory.
Solution:
- Store customer details in a CRM platform or database for easy access and management
- Summarize the current context before each reply
- Inject only relevant information into each prompt
Must Read: 7 Ways AI Healthcare Chatbots are Improving Patient Experience
Conclusion
Token limits may seem like a technical detail, but they define how smart, helpful, and reliable your chatbot truly is.
Even the most advanced AI model has a limited memory window. Understanding token constraints and designing your chatbot to work within or around them is key to delivering consistent, high-quality user experiences.
Want to Build a Chatbot That Doesn’t Forget?
We build intelligent, scalable AI chatbots that remember what matters, perform across long conversations, and stay within token limits.
Contact us today to explore how we can help your business deliver smarter, more reliable AI-powered experiences.
FAQs
Q: What happens when a chatbot hits the token limit?
A: The model starts forgetting earlier parts of the conversation or truncates replies.
Q: How can I increase token limits in ChatGPT?
A: You can’t change the limit, but you can use GPT-4-32k or Claude 2 for larger contexts.
Q: Are tokens the same as words?
A: No, tokens may be whole words, parts of words, or punctuation.
Q: What happens if I exceed the context window in a generative AI tool?
A: Generative AI models have a limit on how much text they can “remember” at once, called the context window (e.g., 500 tokens). If your input exceeds this limit, the model may truncate or ignore earlier parts of your text. This can lead to loss of context, inconsistent storylines, or irrelevant outputs. To maintain coherent and accurate results, keep your input within the context window or provide the story in smaller segments.






